Remove Jira Issue Attachments by MD5 Hash Redux
In my previous post Remove Jira Issue Attachments by MD5 Hash I showed how to remove attachments from JIRA based on the MD5 hash of the attachment.
I was feeling pretty good after writing that post and having eaten my doughnut. So, I went to tell a couple of my colleagues about it. This was their reaction …

So, you expect me to …
- know what an MD5 hash is?
- know how to get the MD5 hash of a file?
- know where to find this script to add the hash to?
- not mess the whole thing up in the process?
Um … uhh … yes? Ok, so maybe my approach isn’t super easy except to the programmer type. And now that I think about it I don’t want to have to be the one to always fix these. So, back to the drawing board. Let’s get this right.
So, I need to make it easy for others than myself to help maintain. Maybe if I made a way for my colleagues to take an attachment from an issue ticket and simply drop to a centralized storage location that could be scanned by the script … yeah that could work. It involves no knowledge of MD5 hashes or scripting and should be easy for pretty much anyone to do.
Now if I only had a location where we could place these attachments. A place that JIRA is able to scan. A place that all my colleagues have easy access to. If only such a place actually existed … hmm … oh, wait!! I could just have them attach the files to another JIRA ticket that will be used as a control ticket of sorts. Any attachments attached to this ticket would be compared against by the script and if a match is found then the issue attachment is deleted. (insert Handel’s Messiah playing in my head here)
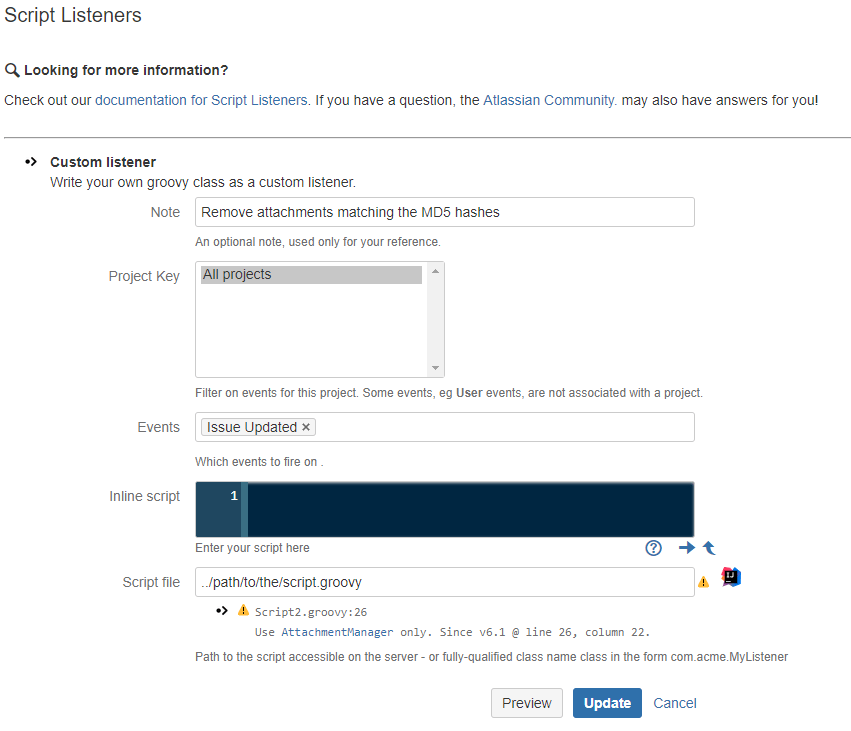
The great thing is that most of my script doesn’t really need to be changed. All I need to do is specify a control ticket key in the script and have the script build the list of hashes based on that ticket. Here is my ticket …
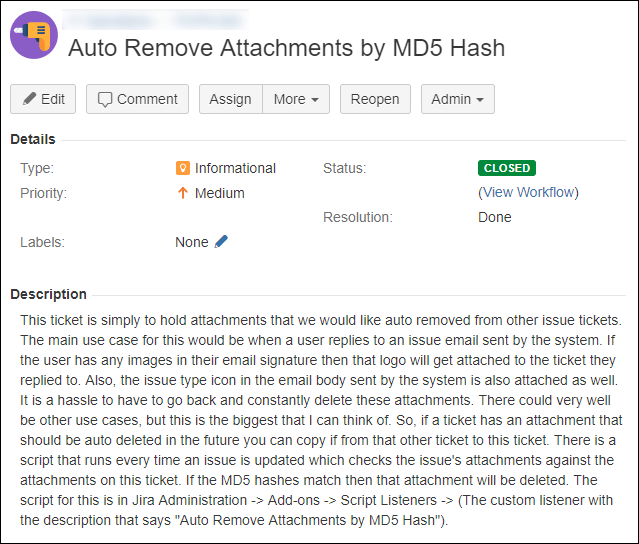
And here is the new script. I’ve cleaned it up a little from the last version and removed a call to a method that is currently set as deprecated. It still worked even with the call, but best to get rid of that call before Atlassian removes the method altogether. Simply replace “{Project Key}-{Issue Number}” on line 12 with the issue key that holds your attachments to remove. So, if for instance the issue is in the FOO project and the issue number is 789 then that line would look like this …
def controlIssue = “FOO-789”;
import com.atlassian.jira.component.ComponentAccessor;
import com.atlassian.jira.issue.AttachmentManager;
import com.atlassian.jira.issue.attachment.FileSystemAttachmentDirectoryAccessor
import com.atlassian.jira.issue.Issue;
import com.atlassian.jira.issue.IssueManager;
import java.security.*;
/***********************************************************************************/
/* This is the ticket that has the attachments on it to compare MD5 hashes against */
/***********************************************************************************/
def controlIssue = "{Project Key}-{Issue Number}";
/***********************************************************************************/
/* */
/***********************************************************************************/
/************************************************************/
/* Don't edit below this unless you know what you are doing */
/************************************************************/
// Get the attachment hashes for our control issue to compare against
def attachmentHashes = getAttachmentHashesFromIssue(controlIssue);
// Obviously we don't want to run this on the control issue ... only on other issues.
if(event.issue.key != controlIssue) {
deleteMatchingAttachments(attachmentHashes);
}
public void deleteMatchingAttachments(List<String> deleteHashes){
def issue = event.issue;
def attachmentManager = ComponentAccessor.getComponent(AttachmentManager);
def attachments = issue.getAttachments();
def attachmentFile = null;
def bytes = null;
def md = MessageDigest.getInstance("MD5");
def digest = null;
def hash = "";
// Loop through each attachment on the issue
for(a in attachments) {
attachmentFile = getAttatchmentFile(issue, a.getId());
bytes = getBytesFromFile(attachmentFile);
digest = md.digest(bytes);
hash = String.format("%032x", new BigInteger(1, digest));
// Compare hash to the list of hashes we don't want
for(h in deleteHashes) {
if(hash == h) {
attachmentManager.deleteAttachment(a);
break;
}
}
}
}
public List<String> getAttachmentHashesFromIssue(String controlIssueKey) {
def deleteHashes = [];
def attachmentManager = ComponentAccessor.getComponent(AttachmentManager);
def issueManager = ComponentAccessor.getComponent(IssueManager);
def issue = issueManager.getIssueObject(controlIssueKey);
def controlIssueAttachments = attachmentManager.getAttachments(issue);
def attachmentFile = null;
def bytes = null;
def md = MessageDigest.getInstance("MD5");
def digest = null;
def hash = "";
// Get hashes for all the attachments in the control issue
for(a in controlIssueAttachments) {
attachmentFile = getAttatchmentFile(issue, a.getId());
bytes = getBytesFromFile(attachmentFile);
digest = md.digest(bytes);
hash = String.format("%032x", new BigInteger(1, digest));
deleteHashes.add(hash);
}
return deleteHashes;
}
public byte[] getBytesFromFile(File file) throws IOException {
def length = file.length();
if (length > Integer.MAX_VALUE) {
throw new IOException("File is too large!");
}
def bytes = new byte[(int)length];
def offset = 0;
def numRead = 0;
def is = new FileInputStream(file);
try {
while (offset < bytes.length && (numRead=is.read(bytes, offset, bytes.length-offset)) >= 0) {
offset += numRead;
}
} finally {
is.close();
}
if (offset < bytes.length) {
throw new IOException("Could not completely read file " + file.getName());
}
return bytes;
}
public File getAttatchmentFile(Issue issue, Long attatchmentId){
return ComponentAccessor.getComponent(FileSystemAttachmentDirectoryAccessor.class).getAttachmentDirectory(issue).listFiles().find({
File it->
it.getName().equals(attatchmentId.toString())
});
}
And now my colleagues sing my praises (in my dreams) instead of cursing my name (which maybe still happens when I make hard to update workflows). Oh well, you live and learn.

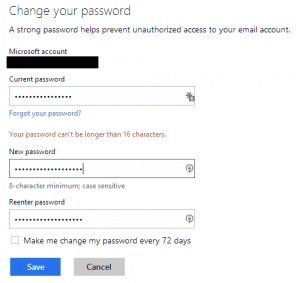 I went to my account and put in a pass phrase that seems pretty decent to me. Here is the first message I got. It seems that my nineteen character passphrase is too long. Why is this an issue I ask? Why does Microsoft care if I want to have a long password? If I want to take on the burden of typing those extra characters what is it to them? This is not a limitation with any other Microsoft system I have ever used (personal machine and work machines). I’m sure their own systems are based on their own stack, so this is an artificial limit that they have put in that has no real value except to make my account easier to hack.
I went to my account and put in a pass phrase that seems pretty decent to me. Here is the first message I got. It seems that my nineteen character passphrase is too long. Why is this an issue I ask? Why does Microsoft care if I want to have a long password? If I want to take on the burden of typing those extra characters what is it to them? This is not a limitation with any other Microsoft system I have ever used (personal machine and work machines). I’m sure their own systems are based on their own stack, so this is an artificial limit that they have put in that has no real value except to make my account easier to hack.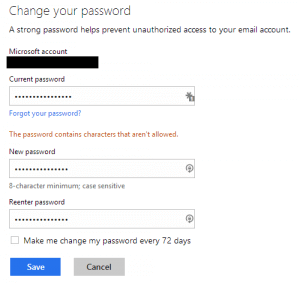 Ok, since I can only have up to sixteen characters in my password I guess I’ll have to comply. Sixteen characters is still pretty long right? So, I swapped out some words and made a few tweaks only to be presented with this. REALLY!? By the way, the character that they do not like is a space. So, I thought I would see what characters they do allow. They allow A-Z, a-z, 0-9, and every special character printed on your keyboard … just not space. Ugh!! It seems they are going out of their way to discourage pass phrases when it has been shown
Ok, since I can only have up to sixteen characters in my password I guess I’ll have to comply. Sixteen characters is still pretty long right? So, I swapped out some words and made a few tweaks only to be presented with this. REALLY!? By the way, the character that they do not like is a space. So, I thought I would see what characters they do allow. They allow A-Z, a-z, 0-9, and every special character printed on your keyboard … just not space. Ugh!! It seems they are going out of their way to discourage pass phrases when it has been shown  Small disclaimer: this works great on my setup. I have not tested it outside of my setup. It should work just fine as I am using the standard API’s that come with Confluence, but it is an open source project and I’m not getting paid for it, so I haven’t done extensive testing in all scenarios.
Small disclaimer: this works great on my setup. I have not tested it outside of my setup. It should work just fine as I am using the standard API’s that come with Confluence, but it is an open source project and I’m not getting paid for it, so I haven’t done extensive testing in all scenarios.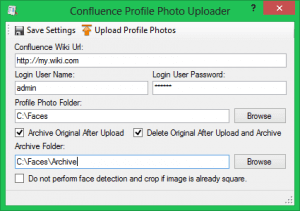 Because of this I decided to write a utility that allows an administrator to sweep in photos in a specified folder with a file mask of “%username%.%extension%” into Confluence. The utility will accept .jpg, .jpeg, .tif, .tiff, .png, and .bmp files. Optionally, you can specify a folder to archive the swept-in photos to after they have been uploaded. Confluence profile photos are 48×48 pixels and since most photos are not square the utility will attempt to do face detection and crop the photo to the largest face in the photo. If the photo is already square you can opt to have the utility not perform the face detection. I am personally not smart enough to write face detection algorithms, so I am using
Because of this I decided to write a utility that allows an administrator to sweep in photos in a specified folder with a file mask of “%username%.%extension%” into Confluence. The utility will accept .jpg, .jpeg, .tif, .tiff, .png, and .bmp files. Optionally, you can specify a folder to archive the swept-in photos to after they have been uploaded. Confluence profile photos are 48×48 pixels and since most photos are not square the utility will attempt to do face detection and crop the photo to the largest face in the photo. If the photo is already square you can opt to have the utility not perform the face detection. I am personally not smart enough to write face detection algorithms, so I am using